How well can AI assemble a machine? The first benchmark results.
We gave three AI workflows the same authored STEP parts and the same goal renders of the finished machine, and asked each to build it, with no instructions on how. We then graded all three the same way. Each placed every part on its own; none is buildable yet.
1. The task, the goal, not the method
The target is the gantry frame of M3-CRETE, an open-source large-format 3D printer / CNC frame: a ~2-metre machine of roughly 100 parts: aluminium extrusions, gantry plates, V-wheels, belts, pulleys, and seven NEMA-23 motors.
Each AI received only two things: the parts kit (the authored CAD files) and four reference renders of the finished machine (a 3/4 overview plus front, top, and side views), plus a short list of design constraints. Critically, we did not give the build sequence. The original human-guided build specified an inside-out order, X axis, then Y, then Z-posts, and detailed steps; here we withheld all of that. The AI had to figure out how to reach the pictured result on its own.

That design choice is the point: MARB tests whether a model understands the mechanical system: here, a V-slot-and-roller gantry, a basic and well-documented pattern, not whether it can follow a recipe. A fairness wall kept each run honest: the driver worked only from the brief and kit, never the reference solution.
2. The grader, one checker, any tool
Every build was graded by CADCLAW, our open-source engine, as a black box: it loads the exported STEP file, no roles, no metadata, labels each solid by its shape signature, and runs three host-agnostic gates:
- Inventory: are all the right parts present, in the right count?
- Interference: do any two solids overlap (a collision)?
- Floating: is every part connected, or is something loose?
Because it grades the exported file rather than a vendor's feature tree, the same procedure judges Fusion, CadQuery, and any AI agent on equal footing. The result feeds the MARB capability ladder (L0–L7) and three positional metrics: GAP (error vs the intended interface gap, ≈0 mm bolted, ≈1 mm motion clearance), ORIENT (% of asymmetric parts in the correct rotation), and POS (position error vs the answer key, both absolute and neighbour‑relative). The ladder then maps onto the TRL / MRL / IRL readiness scales industry already uses.

3. The three drivers
Each ran in a fresh, prompt-only session (no project memory, no answer key):
- Claude-Fusion: Claude Opus 4.7 driving a live Autodesk Fusion via its MCP connection.
- Claude-CadQuery: Claude Opus 4.7 writing a CadQuery (Python) build script.
- Codex-CadQuery: OpenAI Codex (GPT-5), the coding agent (not the chat app), also writing CadQuery.
4. Results
| # | Driver | GAP median ↓ | ORIENT aligned ↑ | POS rel median ↓ | Time | Attempts | Cost (est.) |
|---|---|---|---|---|---|---|---|
| n/a | CADCLAW reference (answer key) | 0.0 mm | 100% | 0.0 mm | resolver | n/a | n/a |
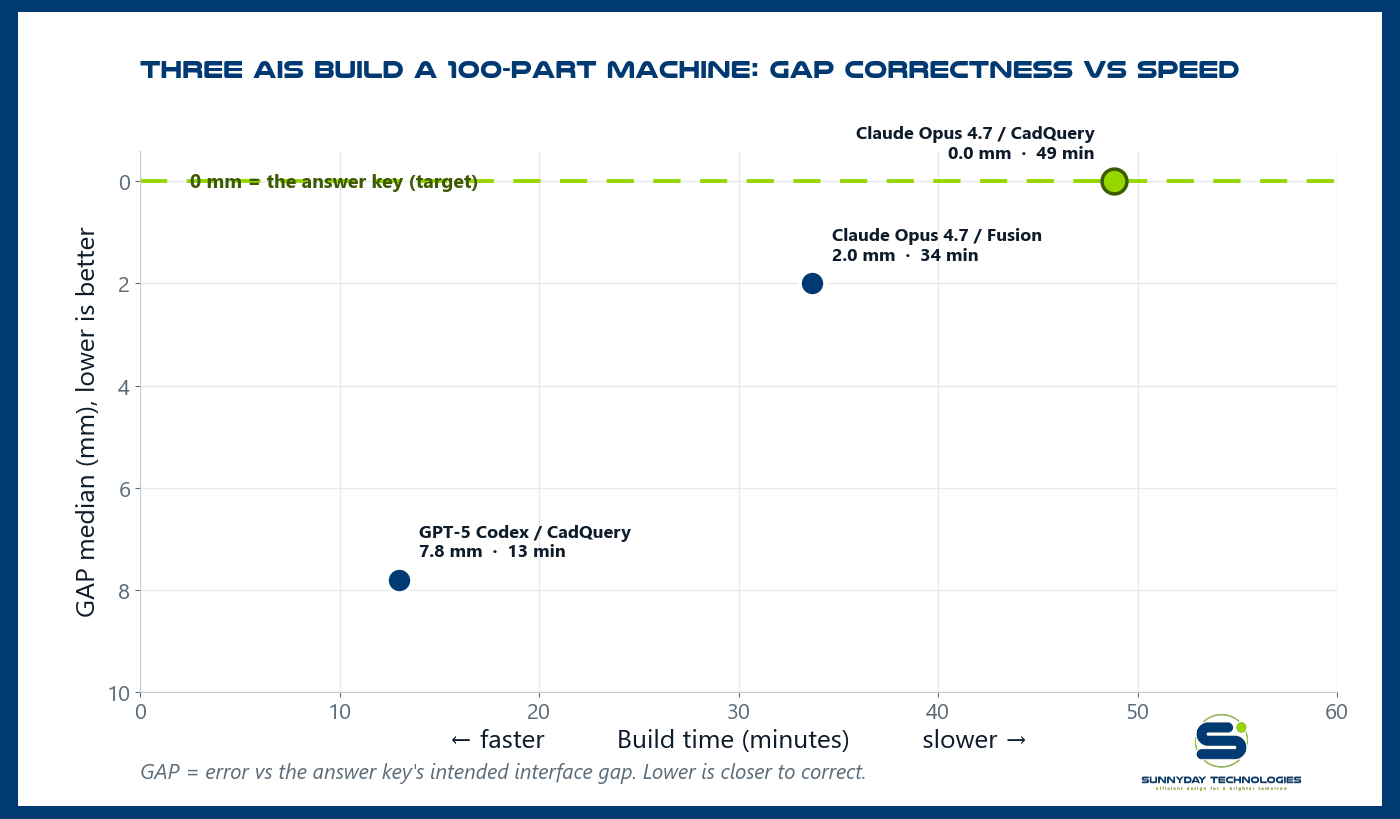
| 1 | Claude Opus 4.7 · CadQuery | 0.0 mm | 51% | 49.9 mm | 48.8 min | 9 | ~$68 |
| 2 | Claude Opus 4.7 · Fusion | 2.0 mm | 47% | 47.7 mm | 33.7 min | 12 | ~$174 |
| 3 | GPT-5 Codex · CadQuery | 7.8 mm | 69% | 47.2 mm | 13.0 min | 1 | not reported |
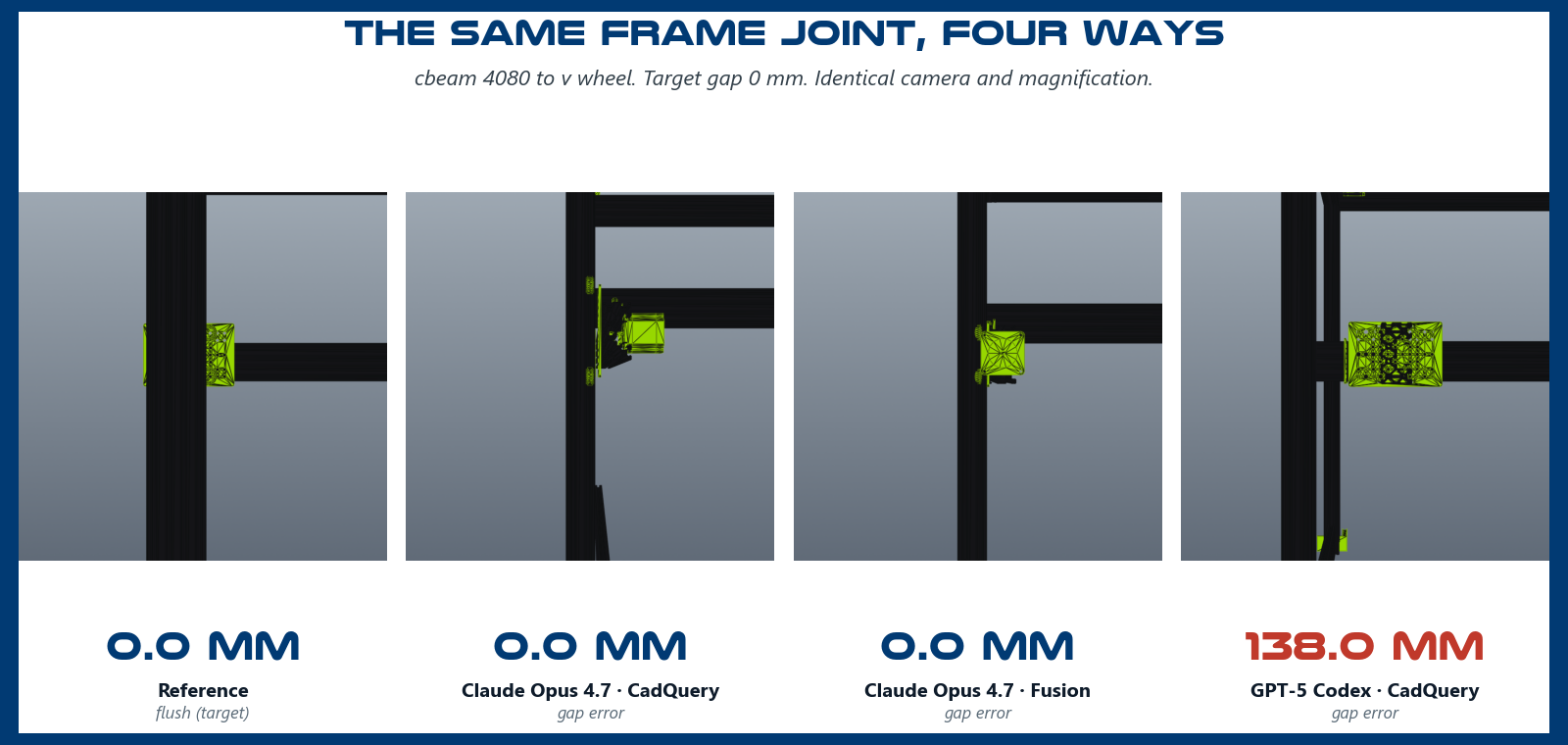
All three got every part in and connected, a real result. None is buildable yet, but the spread shows different models leading different dimensions. Claude‑CadQuery iterated hardest (nine attempts, re‑extracting real hole patterns from the STEPs) and hit the answer key's interface gaps almost exactly, 0 mm median gap error, but took 49 minutes. OpenAI Codex one‑shot the build in 13 minutes (one attempt), fastest by 3–4×, loosest gaps (7.8 mm median), but the most rotations correct (69%). Claude‑Fusion sat in the middle on every axis. More self‑review buys gap precision at the cost of time; Codex shows a single confident pass can still land most parts in the right rotation. (Claude token use, recovered from the run transcripts: 22M and 34M billed, roughly $68 and $174 per run at Anthropic Opus list price; Codex CLI did not expose its count, so its cost is unreported.)
These numbers sit on top of a real result. From the goal renders and the authored STEP parts, with no build sequence, every model produced a coherent ~100‑part machine, and one did it in 13 minutes on the first attempt, with no retries. Tolerances are tight by design, ≤5 mm is "located," ≤5° is "aligned", because real equipment runs on fractions of a millimetre. The remaining gap is precision: getting every interface to its intended gap (0 mm bolted, ~1 mm motion) and every part to the correct rotation. That is what MARB tracks as the models improve.
5. What went wrong, the same failure class
The grader skips accessories (motors, belts, wheels), so every flagged clip is structural metal overlapping structural metal. All three shared the same mistakes: beams placed coincident at the splice joints and post/frame junctions instead of end-to-end, and the centred insert rails overlapping the beams they splice. They got the inventory and the topology right, but not the precise, non-overlapping placement.
There was also an error the current gates do not yet catch: in every run, the Z-posts were turned the wrong way versus the reference. A part that is present, connected, and non-overlapping but mis-oriented passes all three gates today. That is a real defect and a clear next step, an orientation/pose gate, which will rank builds more critically still.
6. Watch them build it
Both CadQuery drivers produced their own review renders as they worked. The Fusion driver inspected via live screenshots that weren't saved, so we recovered its build order afterward by driving the live model through its MCP, revealing the placed parts in sequence under a fixed camera (the design carries no parametric timeline).

7. Limitations & honesty
- A tooling-maturity bias to disclose. CADCLAW and its placement resolver were first built around CadQuery, before the Fusion connection (MCP) existed. The CadQuery runs may therefore carry a home-field edge. We flag it so the comparison stays honest; an orientation gate and more reference tasks will tighten it.
- The reference "100" is our own method. The clean baseline is the spec-driven build (our home workflow) shown as the target, not a neutral third party. We publish the grader and the benchmark scaffold openly so anyone can reproduce, or challenge, these scores.
- Verification is not physical certification. MARB grades geometry and buildability, not real-world performance.
- The scorer is early and version-pinned; effort metrics (time, tokens, attempts) are reported separately and never folded into the artifact score.
- One task, three models: a starting line, not a verdict. More drivers and tasks are coming.
- To our knowledge no prior benchmark grades whole-assembly buildability tool-independently; pairwise-joint datasets (JoinABLe, AutoMate) are the nearest neighbours and address a sub-problem.
8. Why it matters, and what's next
Until recently there was no way to measure this. An AI that can drive CAD, and an automatic checker that confirms whether the result is correct, only recently became usable together. With both in place, the same task can be scored the same way for any tool or model, so improvement is measurable rather than anecdotal.
Next on the curve: a top local model as a low-capability anchor, more frontier drivers, the orientation gate, and additional reference tasks, each plotted as capability vs. MARB score. We are publishing the ladder, the scoring, and the readiness correlation as a candidate standard and inviting labs, CAD vendors, and standards bodies to measure against it.
Reproduce or review: the benchmark scaffold (prompt, scoring, run procedures) and the CADCLAW engine are open. Method overview: marb.cadclaw.io. Benchmark repo (kits, graders, grades): MARB. Engine: CADCLAW. Reviewers welcome, info@sunn3d.com.